Tipología de datos estructurados e introducción a pandas y numpy
En analítica usualmente compartirán una fuente en archivos de texto o facilitarán ingreso a una base de datos; para ello se utilizará la librería de pandas. Además, realizar transformaciones y análisis de información que se convertirán en funciones; para ello numpy es una de librería útil.
Numpy
Es una librería que permite trabajar la información en formato matricial. Similar a las lista de python, pero con mayor eficiencia. Además, existen varias funciones implementadas que facilitan el análisis de información.
Arrays en Numpy: Se puede almacenar información en arreglos n dimensionales. Un escalar es un arreglo de un solo valor. Luego, un arreglo con más de un valor se conoce como vector, muy similar a una lista. Un arreglo bidimensional es una matriz. Por último, esta librería permite crear arreglo con más de dos dimensiones, según sea la necesidad del problema.
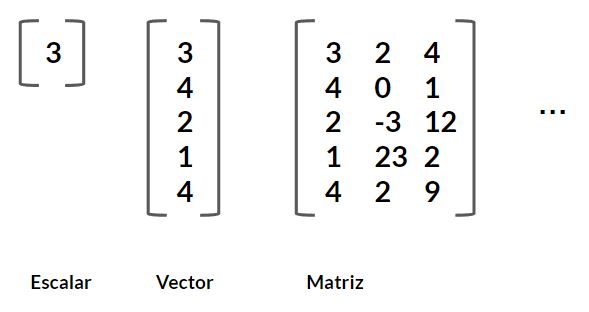 }
}
escalar = np.array([1])
vector = np.array([1,4,5,6])
matriz = np.array([1,4,5,6], [2,4,5,6], [12,23-4])
De ahora en adelante denominares a los arreglos unidimensionales o “n” dimensionales como arreglos o colecciones de manera indistinta (se infiere del código).
Crear arreglos:
Existirán ocasiones donde necesites crear arreglos con características específicas.
Arreglo tradicional
np.array([1,4,5,6])
Arreglo que empiece con 1 y termine en 10 de 2 en 2.
np.arange(start=1, stop=10, step=2)
Arreglo donde especifiques las cantidad de elementos con un inicio y fin
np.linspace(start=11, stop=12, num=18)
Arreglo de ceros
np.zeros(4)
np.zeros((2, 2))
Crear arreglos con números aleatorios:
Arreglos aleatorios enteros
lista_aleatoria = np.random.randint(1,100, size=(1,15))
Número aleatorio real
numero_aleatorio = np.random.rand()
Un arreglo aleatorio a partir de una serie de valores
arreglo_aleatorio = np.random.choice([3, 5, 7, 9], size=(2, 2))
Cambiar la estructura de un arreglo
La nueva estructura tiene que ser poblado con todos los elementos del arreglo inicial, caso contrario encontrarás un error.
arreglo = np.array([1,4,5,6])
arreglo_mod = arreglo.reshape(2,2)
Operaciones básicas
Encontrar el valor máximo de un arreglo
arreglo = np.array([1,4,5,6])
arreglo.max()
Encontrar el índice del valor máximo de un arreglo
arreglo = np.array([1,4,5,6])
arreglo.argmax()
Encontrar el valor mínimo de un arreglo
arreglo = np.array([1,4,5,6])
arreglo.min()
Encontrar el índice del valor mínimo de un arreglo
arreglo = np.array([1,4,5,6])
arreglo.argmin()
Sumar y resta de un escalar o arreglos. Para hacer estas operaciones tienen que tener la misma forma.
arreglo = np.array([1,4,5,6])
arreglo + 2
arreglo - 3
arreglo = np.array([1,4,5,6])
arreglo + arreglo
arreglo - arreglo
Multiplicación y división: tienen que tener en consideración las reglas de multiplicación y división de matrices
arreglo = np.array([1,4,5,6])
arreglo_2 = np.array([3,4,12,6])
arreglo*2
arreglo*arreglo_2
arreglo = np.array([1,4,5,6])
arreglo_2 = np.array([3,4,12,6])
arreglo/2
arreglo/arreglo_2
Otras operaciones
np.sqrt(arreglo)
np.exp(arreglo)
np.sin(arreglo)
np.cos(arreglo)
np.log(arreglo)
Índexación
Indexar hace referencia a obtener elementos específicos dentro de un arreglo. En programación el primer elemento es de índice 0.
arreglo = np.array([0.69, 0.94, 0.66, 0.73, 0.83])
Obtener el primer elemento
arreglo[0]
Último elemento
arreglo[-1]
Todo los elementos a partir del segundo. Para que se incluye el segundo elemento el índice tiene que ser uno anterior.
arreglo[1:]
Hasta el tercer elemento
arreglo[:3]
Cambiar elementos
arreglo[2:5] = 0.5
El operador = crea una referencia, pero no crea una copia de los arreglos. Para ello se utiliza otra función
arreglo_1 = np.array([1,2,3,4])
arreglo_2 = arreglo_1
arreglo_2[0] = -1
arreglo_1 = np.array([1,2,3,4])
arreglo_2 = arreglo_1.copy()
Pandas
Pandas es librería que se utiliza para trabajar bases de datos, ya sea para analizar, limpiar, manipular, entro otros. Una analogía es como tener una hoja excel, pero con muchas más capacidad computacional. El formato es tabular y cada columna puede ser vista como una serie de datos.
Serie de datos
Las series de datos son arreglos unidimensionales que componen una estructura tabular.
serie = pd.Series([1, 3, 5, 12, 6, 8])
Es usual la necesidad de crear variables de formato fecha
dias = pd.date_range("20220101", periods=6)
Al unir más de una serie se obtiene los dataframes.
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list("ABCD"))
Agregar nueva columns o serie
df["Departamento"] = "Lima"
Obtener el formato de cada columna
df.dtypes
Visualizar datos
Obtener los n primeros elementos
df.head(2)
Obtener los n últimos elementos
df.tail(2)
Obtener los índices
df.index
Obtener las columnas
df.columns
Operaciones básicas
Resumen estadísticos de las variables numéricas (enteros o flotante)
df.describe()
Transposición (cambiar filas por columnas)
df.T
Ordernar dataframe por alguna columna
df.sort_index(axis=1, ascending=False)
df.sort_values(by="B")
Indexación o selección
Similar a numpy se pueden seleccion filas, columnas o una combinación de ambas.
Seleccionar columnas
df["A"]
df[["A", "B"]]
Seleccionar filas: se seleccionaran por el índice
df.iloc[3]
Resetear el índice
df = df.reset_index()
Seleccionar diferentes filas y columnas
df.loc[1:4, ["A", "B"]]
Seleccionar con condicional
df[df["A"] > 0]
df["E"] = ["one", "one", "two", "three", "four", "three"]
df[df["E"].isin(["two", "four"])]
Aplicar funciones: si se desea manipular toda una columna se puede utilizar la función apply.
df["A"].apply(lambda x : x*x)
También aplica si es una operación con más de una columna
def sumar_columnas(fila):
return fila["A"] + fila["B"]
df.apply(lambda x : sumar_columnas(x), axis=1)
Leer un archivo excel en formato csv
df_csv = pd.read_csv("air_quality.csv", sep=";")